| 1 Communication | 2 Elements | 3 Engine | 4 Small application | 5 Heavy application | 6 Download | 7 Notes |
![]() 2 Elements of the architecture
2 Elements of the architecture
2.1 Introduction
The main purpose of this section is to give
the reader a view of the inner side of the knowledge engine. This section is
non-technical in the sense that it is not intended as a scientific paper. It is
simplified and incomplete. However, the most important issues will be covered.
The relevant elements of the architecture are discussed: the
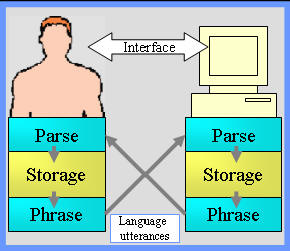
language, the storage and the interface. See illustration 2.1.
| Figure 2.1: Man - machine communication | |
 |
Elements needed Fonal: a formal natural language in which men and machine can express them selves CHI2: a semantic network for storing and retrieving knowledge Interface: dialogs for entering and showing information. |
"Die Grenze meiner Sprache bedeuten die Grenze meiner Welt". Wittgenstein
The design of the language Fonal is profoundly influenced by the previous statement. Translated it says: the limits of my language mean the limits of my world. Suppose you have a 'small language' at your disposal. The world you can express with it will be very limited. If your language is 'big' or has the possibility to grow, the world that it can express will also be 'big' or can become 'big'.
2.2.1 Scalability
Most computer languages are 'small' languages that can not grow. Typically such a language consists of a fixed number of symbols (S) and a fixed number of production rules (R) to glue these words together. A simplified definition of such a computer language (L) will look like this:
L = (S, R) [1]
Symbols you will find in most computer languages are: if then else do for ( ) etc. The rules R determine the order in which the symbols must appear. For example there can be a rule that says that the symbol if must be followed by the symbol ( . Using the symbols and the rules of the language, utterances can be created that can be parsed by the computer. For example
Utterance 1:
if (a == b)
then c = 1;
Utterance 2:
for (i = 0; i < 10; i++)
array[i] = i;
Fonal consists of a variable number of symbols S and a variable number of rules R. It looks like this
L+ = (S+, R+) [2]
By adding new symbols and new rules the language grows. Most of the time these added symbols and rules will be rather concrete, referring to everyday human knowledge.
Utterance 3: SUBJECT
'Patient' 'Patients'.
Utterance 4: SENTENCE A
Patient Always Is A Person.
Utterances 3 and 4 add two symbols to the language: an instance of a subject and an instance of a sentence. The symbol domain S will grow by two. In Fonal sentences are equivalent to rules. So adding utterance 4 to the language also has as a consequence that the rule domain R will grow by one. .
When a language is scalable you can add symbols or rules to it (upsizing). However, it also is possible to remove symbols and/or rules (downsizing). There is no theoretical limit to upsizing. What is the logical limit with respect to downsizing?
2.2.2 Self definition
A second feature of Fonal is its 'self definition'. Of all the configurations of the language there is one in which the language completely defines it self. This can be compared with writing a book in language L (English, Dutch, German, etc.) about language L. This configuration is called L0. The purpose of introducing L0 is to define the logical downsize limit of the language. If you make the language smaller than L0 it will disintegrate and the knowledge engine will come to a halt. L0 consists of a symbol domain S0 and a rules domain R0 like this:
L0 = (S0, R0) [3]
The next utterances describe an important element of S0, the subject: subject (or the class of classes).
Utterance 5: SUBJECT
'Subject' 'Subjects'.
Utterance 6: SENTENCE A
Subject Always Has 1 Or_more Names.
Based on the first word of an utterance the parser of Fonal
retrieves all sentences that have something to say about the utterance. When
utterance 5 is due for parsing, all sentences concerning subjects are retrieved.
In this case that will be utterance 6. Utterance 6 is applied to the remainder
of utterance 5. There it finds two names: 'Subject' and 'Subjects'. The sentence
(utterance 6) has come true and therefore the parser creates an instance of a
subject which happens to be the subject: subject.
As can be easily seen, utterance 5 can not be separated from utterance 6. In
order to parse utterance 5 the sentence has to exist. In order to parse
utterance 6 the subject: subject has to exist.
The definition of other lexical symbols in domain S0
is straight forward. An other example:
Utterance 7: SUBJECT
'Verb' 'Verbs'.
Utterance 8: SENTENCE A
Verb Always Has 1 Or_more Names.
Utterance 9:
VERB
'Has' 'Have'.
Utterance 6 and 8 are rules that define elements of S0. There also are utterances that define the rules: rules about rules . For that reason it is useful to split R0 in a part that defines the basic lexicon (RL, like utterances 6 and 8) and a part that defines the rules (RR):
R0 = (RL, RR) [4]
If the set of rules that defines the rules (RR) is complete, there can be no rule about rules that is not an element of RR. This means that there can be no distinct rules about rules about rules (or any higher). For that reason, the logic that is needed to handle RR will not be higher than predicate logic of the second order.
There are hundreds of languages in which humans express them selves. Each of them has its own lexicon and syntax. Despite these differences human languages have a lot in common. Based on the work of the linguist N. Chomsky we know that human languages have many similar syntactical structures. For example, structures as sentences, noun phrases and verb phrases are found in all human languages. In Fonal we use these universals to define RR, the rules about rules.
As an example, utterance 10 and 11 define a sentence and, for that reason, belong to RR:
Utterance 10: SENTENCE
A Sentence Always Has A NounPhrase.
Utterance 11: SENTENCE A
Sentence Always Has 1 Or_more VerbPhrases.
Utterance 12: GRAMMAR
Sentence 10,11.
If utterance 10 is offered to the parser, it retrieves all
sentences that say something about sentences. In ths case there are two (10 and
11). This is a nice example of self parsing: in order to parse utterance 10 it
needs it self.
Because there are two applicable sentences (10, 11) there exists a decision
problem: which sentence has to be applied first? This is where grammars are
useful. They contain order related information. According to utterance 12,
utterance 10 should be applied before utterance 11. Now the noun phrase of
utterance 10 is 'A Sentence' and the verb phrase is 'Always Has A
NounPhrase'. In this way one can define all the rules of the language.
It should be noted that the order in which sentences are applied differs between natural languages. As an example consider the next utterances
Utterance 13: SENTENCE
A VerbPhrase Always Has A Verb.
Utterance 14: SENTENCE A VerbPhrase Always Has A NounPhrase.
Utterance 15: GRAMMAR VerbPhrase 13,14 [English].
Utterance 16: SENTENCE
Person Has Name.
In utterance 16 'Person' is the noun phrase of the sentence and 'Has Name' is the verb phrase. Within the verb phrase the verb 'Has' comes before the noun phrase 'Name'. That is: in most Germanic languages. There are other languages, like Japanese, in which the verb comes after the noun phrase.
Utterance 17: GRAMMAR VerbPhrase 14.13 [Japanese].
Utterance 18: SENTENCE
Person Name Has.
Table 2.1 gives a summary. Note 7.3 gives a more detailed overview of Fonal and its constituent parts.
| Table 2.1: L+ = ((S0,SX),(RR,RL,RX)) | |||
| Symbol | Description | Defined by | Examples |
| RR | Rules that define rules | RR | Utterance 10, 11 |
| RL | Rules that define basic lexicon S0 | RR | Utterance 6, 8 |
| RX | Rules that define extendable knowledge SX; may be empty | RR | Utterance 19, 20 |
| S0 | Basic lexicon | RL | Utterance 5, 7, 9 |
| SX | Extendable lexicon; may be empty | RX | See figure 2.1 |
2.2.4 The world as it is and as it should be.
Building an application in CommunSENS boils down to describing the relevant world using simple sentences. For example in the world of bills the next utterances will do fine:
Utterance 19: SENTENCE
A Bill Always Has An Amount. [ex ante]
Utterance 20: SENTENCE A
Bill Always Has A Payment. [ex post]
Although the structure of both sentences is
the same, their logic is not because time plays a different role in each of them.
The first sentence must be true before an instance of a bill is created.
After all what's the use of a bill without an amount. These kind of sentences
are called 'ex ante' because they must be true before creation. Ex ante
sentences describe the world as it is. Standard propostion logic can be applied.
The second sentence must become true after creation of the bill. This ex
post sentence describes the world as it should be: bills should be paid.
Unfortunately, applying
standard logic to the ex post
sentence will violate two logical laws. First, the existence of a bill does not
always imply the existence of a payment (Modus Ponens). Second, the
not-existence of a payment does not always imply the not-existence of a bill
(Modus Tollens). For that reason Fonal incorporates
logic that can deal with such time related problems.
If you define in Fonal the world as it is (W1) and the world as it should be (W2), CommunSENS directly deduces which process (and all its intermediate states) leads from W1 to W2. So even programming a process boils down to formulating declarative sentences. In chapter 5 these principles are used in building a heavy business rules case.
2.2.5 Logic
In building the rules about rules (RR) standard proposition and predicate logic was applied with some additions. These additions are necessary to handle second order effects. Basically, these additions handle two questions:
To give an impression of these additions, some examples are given.
Finally a remark on ex post sentences. As mentioned before, one can not reason with ex post sentences without violating proposition logic. However, every ex post sentence can be inverted to an ex ante sentence. For example, utterance 20 can be inverted to:
Utterance 21: A Payment Sometimes Concerns A Bill.
In CommunSENS, reasoning is limited to ex ante sentences (including inverted ex post sentences). Ex post sentences 'an sich' are used to flag the state of the process.
2.2.6 Summary of the features of Fonal.
As has been said, the purpose of this section is to give you a view of the inner side of the knowledge engine. The most import thing to remember about Fonal is
2.3 The semantic network CHI2.
In designing the storage facility of the knowledge engine there was one main goal to be achieved: its architecture should be independent of the information it has to store. For that reason an unrestricted, conventional relational database is not suitable. After all, the architecture of these databases in terms of tables depends on contents. The design of a database for bookkeeping shows an other architecture than the design of a database for a census.
The storage of CommunSENS is a semantic network that consists of three binary relations (= three tables). These relations are based on the three main verbs of Fonal:
R1) A Classifies B
R2) A Has B
R3) A Is B.
The first relation describes the relation between an instance
and its class or subject. In the sentence Socrates Is A Philosopher, the
subject Philosopher classifies a symbol with the name Socrates.
The second relation reflects the connection between symbols that already have
been classified. The Philosopher Socrates Has The Pupil Plato.
The third relation reflects specialization and generalization: The
Philosopher Socrates Is The Person Socrates.
Why are there three relations and not one or five? The answer is surprisingly simple. When there is no specific knowledge about the world the relation between symbols within the symbol domain can only be
Within the semantic network, the storage is symmetric like in double bookkeeping:
S1) Starting with an A you will get
the associated B's
S2) Starting with a B you will get the associated A's.
The name of the network comes from the relations (Classify, Has, Is) and these double (2) entries: CHI2.
It is important to avoid the storage of redundant information. For that reason the equality principles of Leibniz are applied to any piece of added information:
L1) Principle of the equality of what can
not be distinguished.
L2) Principle of the indistinguishability of what is equal.
The following summarizes the characteristics of CHI2:
In the notes section 7.2 there is an detailed example of CHI2.
2.4 Interface
As mentioned in section 1, the transfer of declarative
knowledge between semantic network systems uses language utterances as carriers.
These utterances can be plain text (as the utterances 1 - 21). Utterances also
can be structured in forms. In CommunSENS sentences can be mapped to
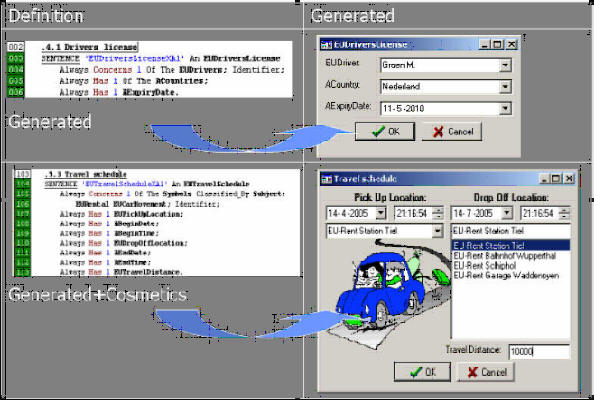
controls on a form. Table 2.2 gives two examples.
Note: the verb 'concerns' is used as a
reciprocal of the verb 'has'.
| Figure 2.2: Generation of the input interface |
|
For more detailed information see
- Note 7.4 User interface
- Note 7.5 Client-server
architecture.
In this section the main elements of the architecture have been discussed: language, storage and interface. The next section wil give an idea about how these elements are used in building the knowledge engine it self.
| 1 Communication | 2 Elements | 3 Engine | 4 Small application | 5 Heavy application | 6 Download | 7 Notes |
Copyright © 2005 by AB Ontwikkeling BV
All Rights Reserved. Any reproduction or reuse of these pages or
their contents requires the advance permission of AB Ontwikkeling BV.